






24
2025
-
12
如何在NVIDIA Jetson平台上运行最新的开源AI模型
浏览:197
发布:2025-12-24 12:00:41
【导语】在小型边缘(yuán)设(shè)备(bèi)上运行先进 AI 与计算机视觉工作流挑战重重,NVIDIA Jetson 平台凭借紧凑 GPU 加速模块与开发套件,满足边缘 AI 与机器人开发需求。本文将介绍在 Jetson 平台运行开源 AI 模型,实现独立运行与部署的方法,包括打造个人 AI 助手、探索机器人技术等内容,还给出 Jetson 选型建议与操作指南,助力开发者构建下一代智能机器。
在小型、低功耗的边缘设备上运行先进的 AI 和计算机视觉工作流正变得越来越具有挑战性。机器人、智能摄像头和自主设备需要实时智能来感知、理解并做出反应,而无需依赖云端。NVIDIA Jetson 平台通过紧凑的 GPU 加速模块和专为边缘 AI 与机器人开发设计的开发套件,满足了这一需求。
本文将介绍如何在 NVIDIA Jetson 平台上运行最新的开源 AI 模型,实现完全独立运行并可随时部署。掌握这些基础知识后,你就可以快速从简单的演示过渡到构建各种应用,比如打造私人代码助手,或者构建完全自主的智能机器人。
教程一:打造你的个人AI助手——本地运行大语言模型与视觉模型
上(shàng)手(shǒu)边(biān)缘(yuán) AI 的(de)一(yī)个(gè)绝(jué)佳(jiā)方(fāng)式(shì),就(jiù)是(shì)在(zài)本(běn)地(de)设(shè)备(bèi)上(shàng)运(yùn)行(xíng)大(dà)语(yǔ)言(yán)模(mó)型(xíng)(LLM)或(huò)视(shì)觉(jué)语(yǔ)言(yán)模(mó)型(xíng)(VLM)。在(zài)自(zì)己(jǐ)的(de)设(shè)备(bèi)上(shàng)直(zhí)接(jiē)运(yùn)行(xíng)这(zhè)些(xiē)模(mó)型(xíng),能(néng)带(dài)来(lái)两(liǎng)个(gè)关键优(yōu)势(shì):完(wán)全的(de)隐(yǐn)私(sī)性(xìng)与(yǔ)零(líng)网(wǎng)络(luò)延(yán)迟(chí)。
当(dāng)使(shǐ)用(yòng)外(wài)部(bù) API 时(shí),数(shù)据(jù)往(wǎng)往(wǎng)需(xū)要(yào)上(shàng)传(chuán)到(dào)云(yún)端(duān),这(zhè)就(jiù)意(yì)味(wèi)着(zhe)失(shī)去(qù)了(le)对(duì)信(xìn)息(xi)的(de)控(kòng)制(zhì)权(quán)。而(ér)在(zài) Jetson 上(shàng),无(wú)论(lùn)是(shì)个(gè)人(rén)笔(bǐ)记(jì)、私(sī)有(yǒu)代(dài)码(mǎ),还(hái)是(shì)摄(shè)像(xiàng)头(tóu)数(shù)据(jù),所(suǒ)有(yǒu)输(shū)入(rù)都(dōu)始(shǐ)终(zhōng)保(bǎo)留(liú)在(zài)本(běn)地(de),确(què)保(bǎo)对(duì)信(xìn)息(xi)的(de)完(wán)全掌(zhǎng)控(kòng)。同(tóng)时(shí),由(yóu)于(yú)无(wú)需(xū)依(yī)赖(lài)网(wǎng)络(luò)传(chuán)输(shū),每(měi)一(yī)次(cì)交(jiāo)互(hù)都(dōu)能(néng)瞬(shùn)间(jiān)响(xiǎng)应(yīng)。
开(kāi)源(yuán)社(shè)区(qū)让(ràng)这(zhè)一(yī)切(qiè)变(biàn)得(de)触(chù)手(shǒu)可(kě)及(jí)。而(ér)能(néng)构(gòu)建(jiàn)出(chū)多(duō)强(qiáng)大(dà)的(de) AI 助(zhù)手(shǒu),很(hěn)大(dà)程(chéng)度(dù)上(shàng)取(qǔ)决(jué)于(yú)选(xuǎn)择(zé)的(de) Jetson 配置:
NVIDIA Jetson Orin Nano Super 开发者套件(8GB):适合打造轻量级专属 AI 助手。你可以轻松部署像 Llama 3.2 3B 或 Phi-3 这类高速“小语言模型”。这些模型不仅推理速度快且都能在 8GB 内存限制下流畅运行,同时 Hugging Face 社区会持续推出针对如编程辅助、创意写作等特定场景的新微调版本。
NVIDIA Jetson AGX Orin(64GB):凭借更大的内存和更强的 AI 算力,它能胜任更大且更复杂的任务,例如用于深度推理的 gpt-oss-20b 或量化版的 Llama 3.1 70B。
NVIDIA Jetson AGX Thor(128GB):拥有高达 128GB 的内存,提供一流的性能。让你能够在边缘端运行参数规模超过 100B 的超大模型,真正把数据中心级别的智能带到边缘端。
如果你手头正好有一台 AGX Orin,现在就可以动手试试:用 vLLM 作为推理引擎,搭配界面友好、美观易用的 Open WebUI,很快就能启动一个 gpt-oss-20b 实例。
docker run --rm -it \ --network host \ --shm-size=16g \ --ulimit memlock=-1 \ --ulimit stack=67108864 \ --runtime=nvidia \ --name=vllm \ -v $HOME/data/models/huggingface:/root/.cache/huggingface \ -v $HOME/data/vllm_cache:/root/.cache/vllm \ ghcr.io/nvidia-ai-iot/vllm:latest-jetson-orin vllm serve openai/gpt-oss-20b
在另一个终端中运行 Open WebUI:
docker run -d \ --network=host \ -v ${HOME}/open-webui:/app/backend/data \ -e OPENAI_API_BASE_URL=http://0.0.0.0:8000/v1 \ --name open-webui \ ghcr.io/open-webui/open-webui:main
然后查阅:http://localhost:8080
在此基础上,你可以与大语言模型进行自然交互,并进一步为它集成各种工具,使其具备智能体能力,比如搜索、数据分析及语音输出(TTS)。
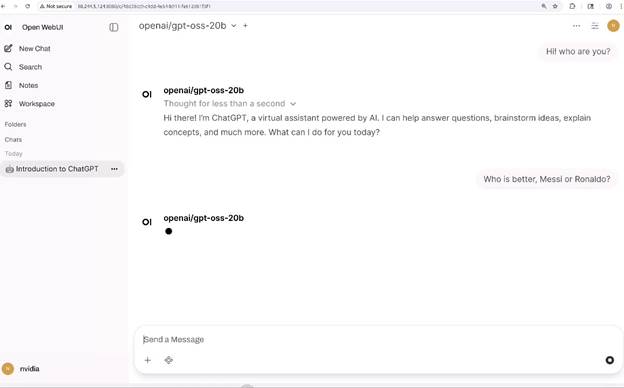
图 1. 基于 Jetson AGX Orin,通过 Open WebUI 界面使用 vLLM 进行 GPT-OSS 20B 模型推理的演示,生成速度达每秒 40 个 token
然而,仅靠文本还不足以构建能真正与物理世界交互的智能体,它需要具有多模态感知能力。在这方面,既能识别画面中的物体,又能对整个场景进行推理的视觉语言模型正成为主流选择,比如 VILA 和 Qwen2.5-VL。面对一段实时视频流,这类模型可以回答如“这次 3D 打印是不是失败了?”或“外面现在的交通状况怎么样?”等问题。
Jetson Orin Nano Super 开发者套件可以运行像 VILA-2.7B 这类高效的视觉语言模型,来完成基础检测和简单的视觉查询任务。Jetson AGX Orin 凭借更大的内存和更强的算力,能从容应对更复杂、更密集的工作负载,如处理更高分辨率的画面、同时接入多路摄像头或者并行运行多个智能体。
要亲身体验这一能力,可直接从Jetson AI Lab启动Live VLM WebUI。它能通过 WebRTC 将电脑的实时摄像头画面传输给 AI 模型,让模型即时分析并描述,相当于搭建了一个沙盒。
Live VLM WebUI 兼容 Ollama、vLLM,以及几乎所有支持 OpenAI 服务器协议的推理引擎。
若想通过 Ollama 启动 VLM WebUI,可按以下步骤操作:
# Install ollama (skip if already installed)curl -fsSL https://ollama.com/install.sh | sh # Pull a small VLM-compatible modelollama pull gemma3:4b # Clone and start Live VLM WebUIgit clone https://github.com/nvidia-ai-iot/live-vlm-webui.gitcd live-vlm-webui./scripts/start_container.sh
体验该功能请查阅:https://localhost:8090
从此开始,构建智能安防系统、野生动物观察助手或视觉辅助应用。
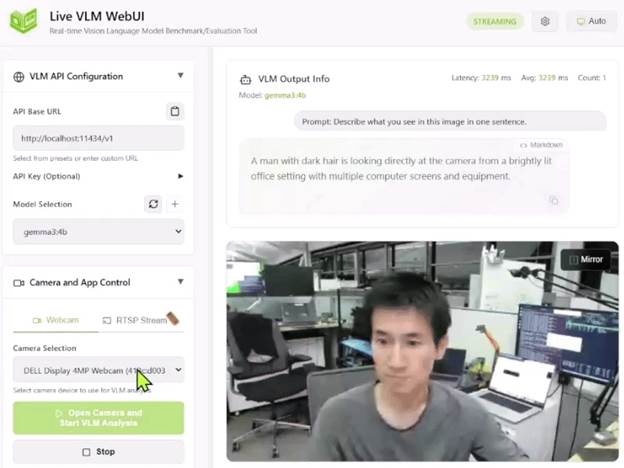
图 2. 在 NVIDIA Jetson 上通过 Live VLM WebUI 实现交互式视觉语言模型推理
可以运行哪些视觉语言模型?
Jetson Orin Nano 8GB:适合运行参数量最高约 4B 的视觉语言模型,例如 Qwen2.5-VL-3B、VILA 1.5–3B 或 Gemma-3/4B。
Jetson AGX Orin 64GB:适合运行参数量级约为 4B 至20B 的中型视觉语言模型,例如 LLaVA-13B、Qwen2.5-VL-7B、Phi-3.5-Vision。
Jetson AGX Thor 128GB:专为超大规模模型设计,可支持约 20B 至 120B 参数的单个模型或多个模型并行运行,例如 Llama 3.2 Vision 70B 或120B量级的模型。
想探索更深层的应用?视频搜索和总结(VSS)能力可助力构建智能化视觉档案系统。这意味着可以直接根据视频中的内容进行检索而不只局限于搜索文件名,还能为长时间录像自动生成内容摘要。对希望高效管理并深度挖掘视觉数据价值的开发者而言,这正是视觉语言模型理念的完美延伸。
教程二:基于基础模型的机器人技术
机器人领域正经历一场根本性的架构变革。数十年来,机器人控制主要依赖于僵化的硬编码逻辑与割裂的感知流程:先检测物体、再规划路径、最后执行动作。每一种可能的边缘情况都需要人工反复调试和显式编程,使大规模自动化难以实现。
如今,机器人领域正朝着端到端模仿学习的方向演进:不再需要编写显式规则,而是借助如NVIDIA Isaac GR00T N1这样的基础模型,直接从演示中学习控制策略。这类视觉语言动作模型从根本上改变了机器人控制的输入输出关系。在此架构下,模型接收来自机器人摄像头的实时视觉数据流,结合自然语言指令(例如:“打开抽屉”),处理(lǐ)这(zhè)些多模态上下文信息,直接预测下一刻所需的关节位置或电机转速。
然而,训练这些模型面临着一个重大挑战:数据瓶颈。与语言模型可利用海量互联网文本进行训练不同,机器人需要的是物理交互数据,这类数据的采集成本高昂且获取速度慢。解决这一难题的关键在于仿真。借助NVIDIA Isaac Sim,不仅可以在物理精确的虚拟环境中生成合成训练数据并验证控制策略,还可以进行硬件在环测试:让 Jetson 连接到由NVIDIA RTX GPU 驱动的仿真器,并运行控制策略。这样一来,在投资实体硬件或进行实地部署之前,你就能验证从感知到执行的完整端到端系统。
在仿真中完成验证后,整个工作流可以无缝迁移到真实世界。您可以将优化后的策略直接部署到边缘设备,并借助 TensorRT 等优化技术,让原本复杂的 Transformer 也能以实时控制循环所需的低延迟(低于 30 毫秒)运行。无论是构建简单的机械臂,还是探索更复杂的人形机器人,这种“在仿真中学习动作,再部署到物理边缘”的方法,如今已成为现代机器人开发的标准流程。
现在即可尝试这些开发流程。GitHub 上的 Isaac Lab 评估任务库内置了螺母分拣、排气管分类等工业级操作基准测试场景。开发者可先在仿真环境中验证控制策略,再部署到实体硬件。通过验证后,GR00T Jetson 部署指南将引导开发者将策略转换为 TensorRT 优化格式,确保其在 Jetson 平台的高效运行。针对需在自定义任务中后训练或微调 GR00T 模型的开发者,LeRobot 集成方案整合了社区数据集与模仿学习工具,打通从数据采集到实际部署的全链路。
加入机器人开发者社区:机器人开发者社区正蓬勃发展,成为技术探索的热土。从开源机器人设计到共享学习资源,这条创新之路始终充满同行者。各类技术论坛、GitHub 开源项目以及社区成果展示,将持续为你提供灵感与实践指导。欢迎加入 LeRobot Discord 社区,与全球机器人开发者沟通交流,共同塑造机器人的未来。
构建实体机器人需投入大量精力在机械设计、组装还有与现有平台集成。但真正驱动机器人的“智能层”又该如何实现?这正是 Jetson 的价值所在:实时、强大且可立即部署。
哪款Jetson最适合你?
Jetson Orin Nano Super(8GB)适(shì)合(hé)刚(gāng)接(jiē)触(chù)本(běn)地(de) AI,想(xiǎng)运(yùn)行(xíng)较(jiào)小(xiǎo)的(de) LLM 或(huò) VLM 模(mó)型(xíng)或(huò)进(jìn)行(xíng)早(zǎo)期(qī)机(jī)器(qì)人(rén)及(jí)边(biān)缘(yuán)原(yuán)型(xíng)开(kāi)发(fā)的(de)开(kāi)发(fā)者(zhě)。相(xiāng)比(bǐ)于(yú)考(kǎo)虑(lǜ)最(zuì)大(dà)模(mó)型(xíng)容(róng)量(liàng),它(tā)体(tǐ)积(jī)小(xiǎo)巧(qiǎo)、价(jià)格亲民、上手简单,更适合机器人项目和嵌入式应用的开发爱好者。
Jetson AGX Orin(64GB)适合希望打造功能扎实的本地 AI 助手、尝试智能体式工作流或构建能实际部署的个人应用的爱好者或独立开发者。64GB 内存让你无需为内存不足而烦恼,可直接在一台设备上轻松组合视觉、语言和语音模型(ASR 和 TTS)。
Jetson AGX Thor(128GB)适合对需要处理超(chāo)大(dà)规(guī)模(mó)模(mó)型(xíng)、同(tóng)时(shí)运(yùn)行(xíng)多(duō)个(gè)模型或者在边缘侧对实时性有严苛要求的开发者。
操作指南
准备好开始探索了吗?按以下步骤快速入门:
选择适合你的Jetson:根据你的目标和预算,挑选适合你需求的开发者套件。
刷写系统与配置:快速入门指南将让设置过程变得简单直接,你可以在一个小时内完成准备工作并开始运行。
Jetson Orin Nano 开发者套件——快速入门指南
Jetson AGX Orin 开发者套件——快速入门指南
Jetson AGX Thor 开发者套件——快速入门指南
探索生态资源:
Jetson AI Lab:访问包含全面教程与预建容器指引的资源库(Open WebUI、Live VLM WebUI等),测试你的模型。
社区论坛:与其他开发者交流、分享项目并获取帮助
动手构建:选择一个项目,深入学习 GitHub 上的教程项目,看看能做到什么,并继续深入探索。
NVIDIA Jetson 系列产品为开发者提供了设计、构建和部署下一代智能机器所需的全套工具。
关于作者
Chitoku Yato 是节能、紧凑和可扩展的 NVIDIA Jetson Edge AI 平台的技术产品营销经理,负责确保平台上的最佳开发人员体验。他还与充满活力的 NVIDIA 开发人员社区密切合作,帮助宣传在 Jetson 上使用预训练的 AI 模型、开发人员 SDK 和对云原生技术的支持,以帮助客户构建、部署和管理基于 AI 的自主机器。这包括关于 NVIDIA JetBot 和 JetRacers 的教程以及关于 NVIDIA 深度学习学院的教育内容,以教授和学习 AI 和机器人技术。他在东京的索尼公司开始了他的职业生涯,在那里他从事 GPS 汽车导航系统开发、Android 平板电脑软件开发和 PlayStation 外围设备的产品规划。 Chitoku 拥有加州大学圣巴巴拉分校的计算机工程学士学位。
Khalil BenKhared 是 NVIDIA Jetson 团队的技术营销工程师。Khalil 拥有创建和扩展 AI 和机器人开发解决方案的背景,他喜欢从根本上简化边缘 AI,让开发者和工程师更容易使用。
相关新闻







联系我们
地址:山东省济南市槐荫区兴福街道齐鲁大道3189号西进时代中心
电话:15898523365
传真:15898523365
邮箱:service@Kaiyun.cco
网址:http://www.rjptj.com

