






14
2025
-
03
破解透明物体抓取难题,地瓜机器人 CASIA 推出几何和语义融合的单目抓取方案|ICRA 2025
浏览:485
发布:2025-03-14 13:00:28
概述
近日,全球机器人领域顶会ICRA 2025(IEEE机器人与自动化国际会议)公布论文录用结果,地瓜机器人主导研发的DOSOD开放词汇目标检测算法与MODEST单目透明物体抓取算法成功入选。前者通过动态语义理解框架提升复杂场景识别准确率,后者结合几何建模与语义分析技术优化透明物体操作精度,两项技术成果均已在规模化商业场景中得到有效验证。此次投稿的两篇论文全部入选,不仅彰显了ICRA对机器人感知领域的高度重视,同时也印证了地瓜机器人团队在机器人视觉领域的领先优势。
DOSOD开放词汇目标检测算法,本期文章将围绕MODEST单目透明抓取算法进行重点介绍。
作为机器人执行各项任务中绕不开的操作对象,水杯、试管、窗户等透明物体在人类生活中无处不在。从精密制造、医疗实验室和家庭服务机器人等领域,透明物体的精确操作是提升自动化和智能化水平的关键。然而,透明物体复杂的折射和反射特性给机器人感知造成了很大困难。在大多数RGB图像中的透明物体往往缺乏清晰的纹理,而容易与背景混为一体。此外,商用深度相机也难以准确捕捉这些物体的深度信息,导致深度图缺失或噪声过多,从而限制了机器人在多个领域的广泛应用。
为了解决透明物体的抓取问题,地瓜机器人联合中科院自动化所(简称:CASIA)多(duō)模(mó)态(tài)人工智能系统全国重点实验室,推出了针对透明物体的单目深(shēn)度(dù)估(gū)计(jì)和(hé)语(yǔ)义(yì)分(fēn)割(gē)的(de)多(duō)任(rèn)务(wu)框(kuāng)架(jià)(简(jiǎn)称(chēng):MODEST)。该(gāi)框(kuāng)架(jià)借(jiè)助(zhù)创(chuàng)新(xīn)性(xìng)的(de)语(yǔ)义(yì)和(hé)几(jǐ)何(hé)融(róng)合(hé)模(mó)块(kuài),结(jié)合(hé)独(dú)特的特征迭代更新策略,显著提升了深度估计和语义分割的效果,尤其在抓取成功率和系统泛化性方面取得了突破性进展。
MODEST算法框架作为通用抓取模型的前置模块,即插即用,灵活高效,且无需依赖额外传感器,仅靠单张RGB图像,便可实现透明物体的抓取,效果上甚至要优于其它双目和多视图的方法,可以广泛应用于智能工厂(chǎng)、实(shí)验(yàn)室(shì)自动化、智慧家居等场景,降低设备成本并大幅提升机器人对透明物体的操作能力。
基本原理
当前透明物体的抓取核心在于深度信息的获取,目前无论是深度传感器还是多视角重建的方法都无法获取透明物体准确完整的深度信息。为了解决透明物体感知难题,传统方法大多依赖特殊传感设备或多视角图像,增加了时间和经济成本,并常常受限于应用场景。MODEST单目框架首次突破了传统传感器处理透明物体时的限制,降低了设备成本和使用复杂度,提供了更加高效、经济和便捷的透明物体感知方案。
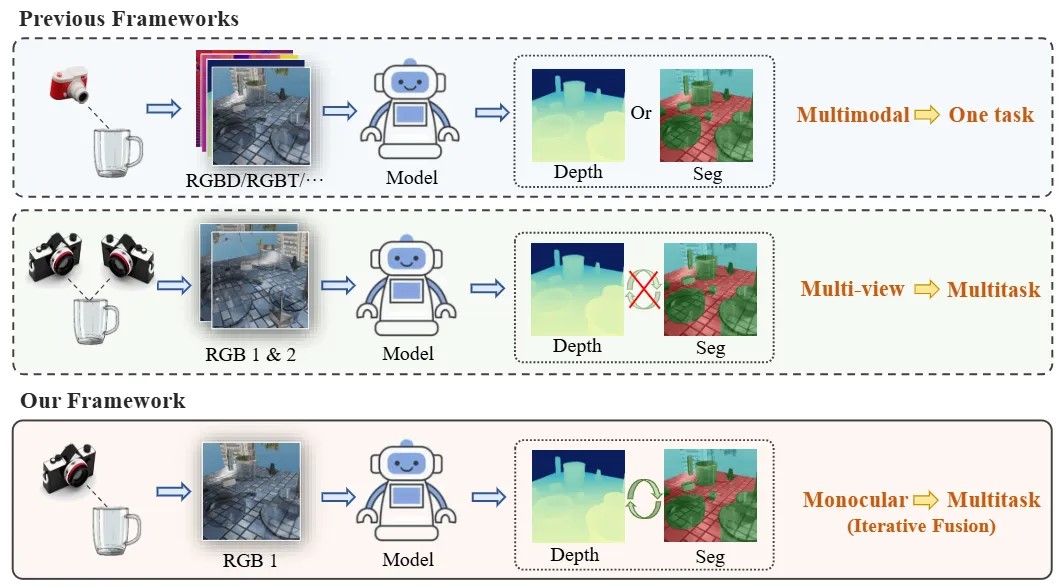
单目透明物体感知框架与其他方法之间的对比
MODEST主要聚焦于透明物体的深度估计,通过设计的语义和几何结合的多任务框架,获取物体准确的深度信息,之后结合基于点云的抓取网络实现透明物体的抓取。相当于在通用抓取网络前面增加一个针对透明物体的增强模块。
MODEST模型的整体架构如图所示,输入为单目RGB图像,输出为透明物体的分割结果和场景深度预测。网络主要由编码、重组、语义几何融合和迭代解码四个模块组成。输入图像首先经过基于ViT的编码模块进行处理,随后重组为对应分(fēn)割(gē)和(hé)深(shēn)度(dù)两(liǎng)个(gè)分(fēn)支(zhī)的(de)多(duō)尺(chǐ)度(dù)特征。在融合模块中对两组特征进行混合和增强,最后通过多次迭代逐步更新特征,并获得最终预测结果。
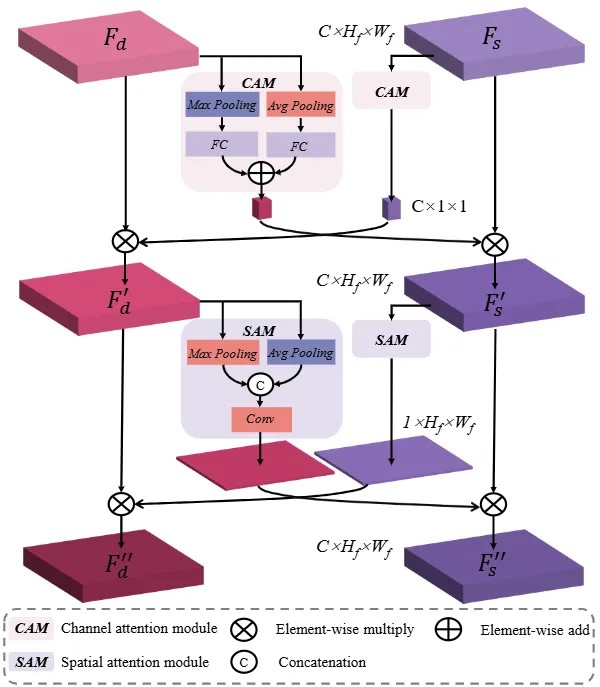
基于语义几何融合和迭代策略的透明物体单目多任务框架
对于透明物体来说,语义分割任务可以为深度估计提供语义和上下文信息,而同样深度估计可以为分割提供边界、表面等几何信息。为了充分挖掘两个任务间的互补信息,MODEST算法框架构建了基于注意力机制的语义几何融合模块,旨在同时提升两个任务的性能。
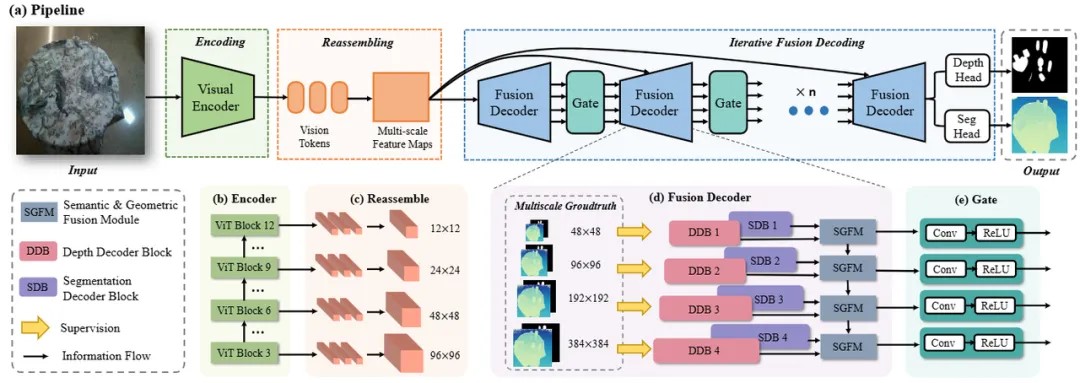
语义几何融(róng)合(hé)模(mó)块(kuài)结(jié)构(gòu)
当人类观察透明物体等不显著物体时,我们会倾向于先注意物体的整体轮廓,然后是局部细节。受人眼启发,MODEST框架提出了一种由粗到细的特征更新策略,进一步提升预测精度。
实验结果
为了测试MODEST全新算法框架的检测效果,我们选取了透明物体领域两个影响力广泛的公开仿真数据集Syn-TODD和真实数据集ClearPose,在其上与目前最先进的透明物体双目方法SimNet、多视图方法MVTran以及多任务方法InvPT和TaskPrompter进行对比实验。两个大规模数据集都拥有超过100k的良好标注图像数据,并且包含了严重遮挡等极端场景。
公开数据集上的定(dìng)性(xìng)和(hé)定(dìng)量对比实验
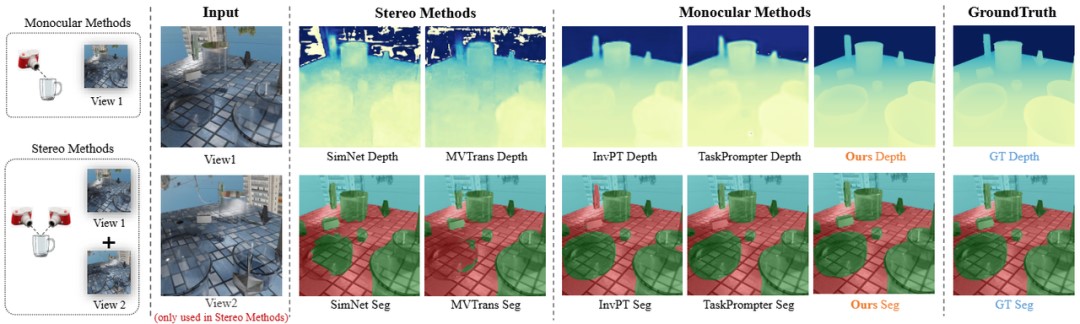
仿(fǎng)真(zhēn)数(shù)据(jù)集Syn-TODD上(shàng)的(de)定(dìng)性(xìng)对(duì)比(bǐ)结(jié)果(guǒ)
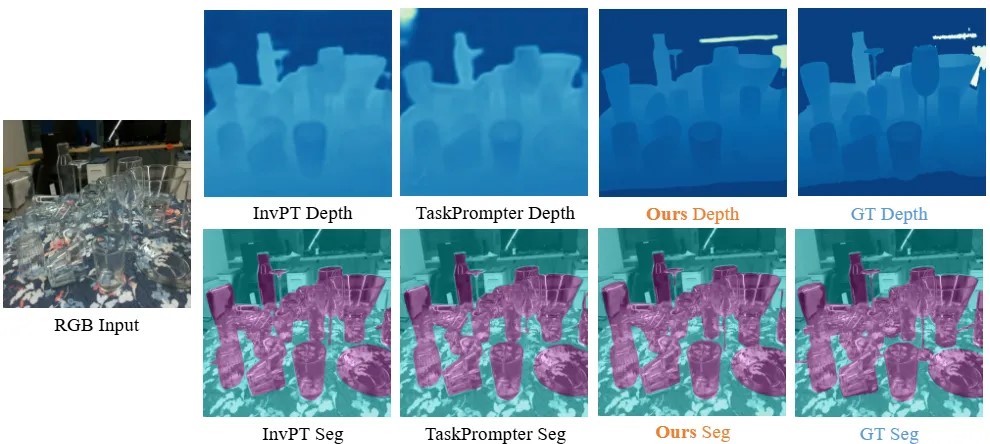
真(zhēn)实(shí)数(shù)据(jù)集ClearPose上(shàng)的(de)定(dìng)性(xìng)对(duì)比(bǐ)结(jié)果(guǒ)
通(tōng)过(guò)在(zài)两(liǎng)个(gè)数(shù)据(jù)集上(shàng)的(de)定(dìng)性(xìng)对(duì)比(bǐ)结(jié)果(guǒ)可(kě)以(yǐ)看(kàn)出(chū),由(yóu)于(yú)透(tòu)明(míng)物(wù)体(tǐ)会(huì)错(cuò)误(wù)地(de)折(zhé)射(shè)背(bèi)景(jǐng),并(bìng)且(qiě)在(zài)RGB图(tú)像(xiàng)中(zhōng)缺(quē)乏(fá)纹(wén)理(lǐ),因(yīn)此(cǐ)SimNet、MVTrans等(děng)方(fāng)法(fǎ)无(wú)法(fǎ)获(huò)得(de)令(lìng)人(rén)满(mǎn)意(yì)的(de)预(yù)测(cè),从(cóng)而(ér)导(dǎo)致(zhì)深(shēn)度(dù)图(tú)和(hé)分(fēn)割(gē)掩(yǎn)膜(mó)的(de)大(dà)面(miàn)积(jī)缺(quē)失(shī)。然(rán)而(ér),通(tōng)过(guò)有(yǒu)效(xiào)的(de)融(róng)合(hé)和(hé)迭(dié)代(dài),在(zài)某(mǒu)些(xiē)即(jí)使(shǐ)人(rén)眼(yǎn)都(dōu)难(nán)以(yǐ)分(fēn)析(xī)和(hé)判(pàn)断(duàn)的(de)场(chǎng)景(jǐng),我(wǒ)们(men)的(de)方(fāng)法(fǎ)依(yī)然(rán)能(néng)够(gòu)产(chǎn)生(shēng)完(wán)整(zhěng)和(hé)清(qīng)晰(xī)的(de)预(yù)测(cè)结(jié)果(guǒ)。
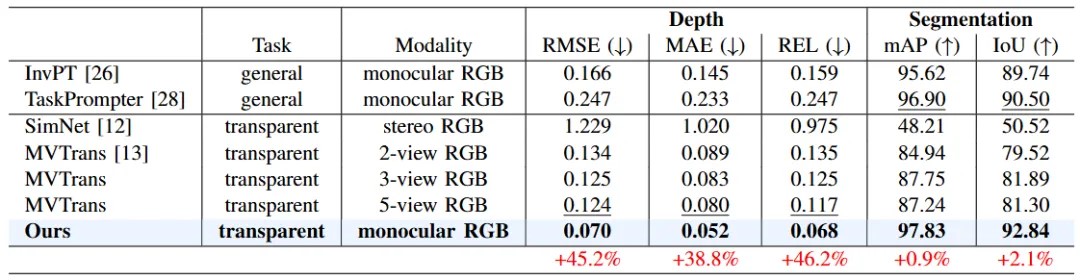
仿真数据集Syn-TODD上的定量对比结果
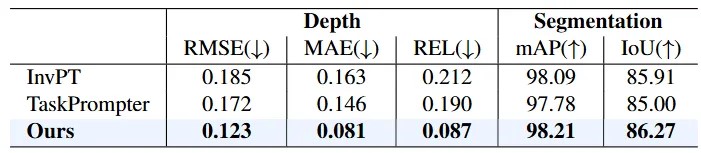
真实数据集ClearPose上的定量对比结果
从表格中的定量对比可以看出,MODEST算法框架在各项指标上都要大幅超过其他所有方法。值得注意的是,尽管只使用单张RGB图像作为输入,MODEST在深度估计和语义分割方面都要明显优于其他双目甚至多视图方法。并且在Syn-TODD数据集上,与排名第二的方法相比,MODEST算(suàn)法(fǎ)框(kuāng)架(jià)在(zài)RMSE和REL两项指标有着超过45%的提升,语义分割的精度也均超过了90%。
真实平台抓取实验
我们将算法迁移到真实机器人平台,开展了透明物体抓取实验。平台主要由UR机械臂和深度相机构成,在借助MODEST方法进行透明物体精确感知的基础之上,采用GraspNet进行抓取位姿的(de)生成。在多个透明物体上的实验结果表明,MODEST方法在真实平台上具有良好的鲁棒性和泛化性。
相关新闻







联系我们
地址:山东省济南市槐荫区兴福街道齐鲁大道3189号西进时代中心
电话:15898523365
传真:15898523365
邮箱:service@Kaiyun.cco
网址:http://www.rjptj.com

